

Note: The full application code for this guide is available at the bottom of the page.
- Understand and extend a robust agentic workflow for any tabular data challenge
- Integrate AI-powered code generation and validation into your data pipelines
Overview
This app uses three agents:- Analyst Agent: Examines the uploaded dataset and creates a cleaning plan.
- Coder Agent: Generates Python code to clean the dataset.
- Validator Agent: Tests and fixes the generated code, ensuring robust results. Fallback logic ensures your data is cleaned even if the API is unavailable.
Prerequisites:
- Python 3.8+
- Packages:
streamlit,pandas,requestsInstall dependencies:
Copy
pip install streamlit pandas requests
Meet the Agents: How the System Works
The Enhanced Data Preprocessor Agent System is powered by three intelligent agents, each designed to automate a specific stage of the data cleaning workflow. Here’s how they work together:Analyst Agent
This agent is your data detective. It:- Scans your uploaded dataset for missing values, duplicates, and unusual patterns
- Detects column types (numeric, categorical, date, etc.)
- Summarizes key issues and generates a prioritized cleaning plan using AI
- Example output: “Found 1,200 missing values in 3 columns; detected 2 date columns; 5% duplicate rows”
Coder Agent
This agent is your code generator. It:- Reads the Analyst’s cleaning plan and dataset analysis
- Uses AI to write a custom Python function (using pandas) to clean your data
- Handles missing values, removes duplicates, converts date columns, and more
- Ensures the code is robust, readable, and includes error handling
- Example output: A function like
def clean_dataset(df): ...tailored to your data
Validator Agent
This agent is your code tester and fixer. It:- Runs the generated cleaning code on your dataset
- Detects and fixes errors automatically using AI (e.g., wrong column names, type mismatches)
- Validates that the cleaned data matches expectations (no missing values, correct types, etc.)
- Falls back to a built-in cleaning routine if the AI code fails
- Example output: “Success! Cleaned 10,000 → 9,800 rows; missing values reduced by 90%”
- Analyst Agent analyzes the data and creates a cleaning plan.
- Coder Agent generates cleaning code based on the plan.
- Validator Agent tests and fixes the code, ensuring the output is correct.
- You download the cleaned dataset and a detailed report.
- Each agent is modular and extensible—you can add more agents for advanced tasks (feature engineering, outlier detection, etc.)
- The system is robust: if the AI code fails, fallback logic ensures your data is still cleaned
- You get transparency: all agent decisions, code, and results are visible in the UI
User Experience & Key Features
The Enhanced Data Preprocessor Agent System is designed to deliver a seamless and transparent user experience, ensuring both reliability and clarity throughout the data cleaning process:- Intuitive Interface: The application leverages Streamlit’s interactive components—including expanders, columns, and metrics—to present information in a clear and accessible manner.
- Full Transparency: All agent actions, generated code, and results are displayed to the user, providing complete visibility into each step of the workflow.
- Instant Data Export: Users can download the cleaned dataset immediately upon completion, streamlining integration into downstream processes.
- Robust Error Handling: Advanced fallback logic guarantees that data cleaning is completed successfully, even in the event of API or code generation failures.
Example Outputs
Analysis Report:- Issues: Missing values, duplicates, data type mismatches
- Columns by type: Numeric, categorical, datetime
- Fill missing values
- Remove duplicates
- Convert date columns
- Rows removed, missing values reduced, duplicates removed, data type improvements
Tips for Customization
- Adjust agent prompts for your specific data domain.
- Add more agents for advanced tasks (feature engineering, outlier detection).
- Use Streamlit widgets for richer interactivity.
Results and Advanced Analytics
Explore the advanced analytics and results generated by the Data Preprocessor Agent. This includes visualizations, statistical summaries, and other insights that help you understand your data better and validate the cleaning process.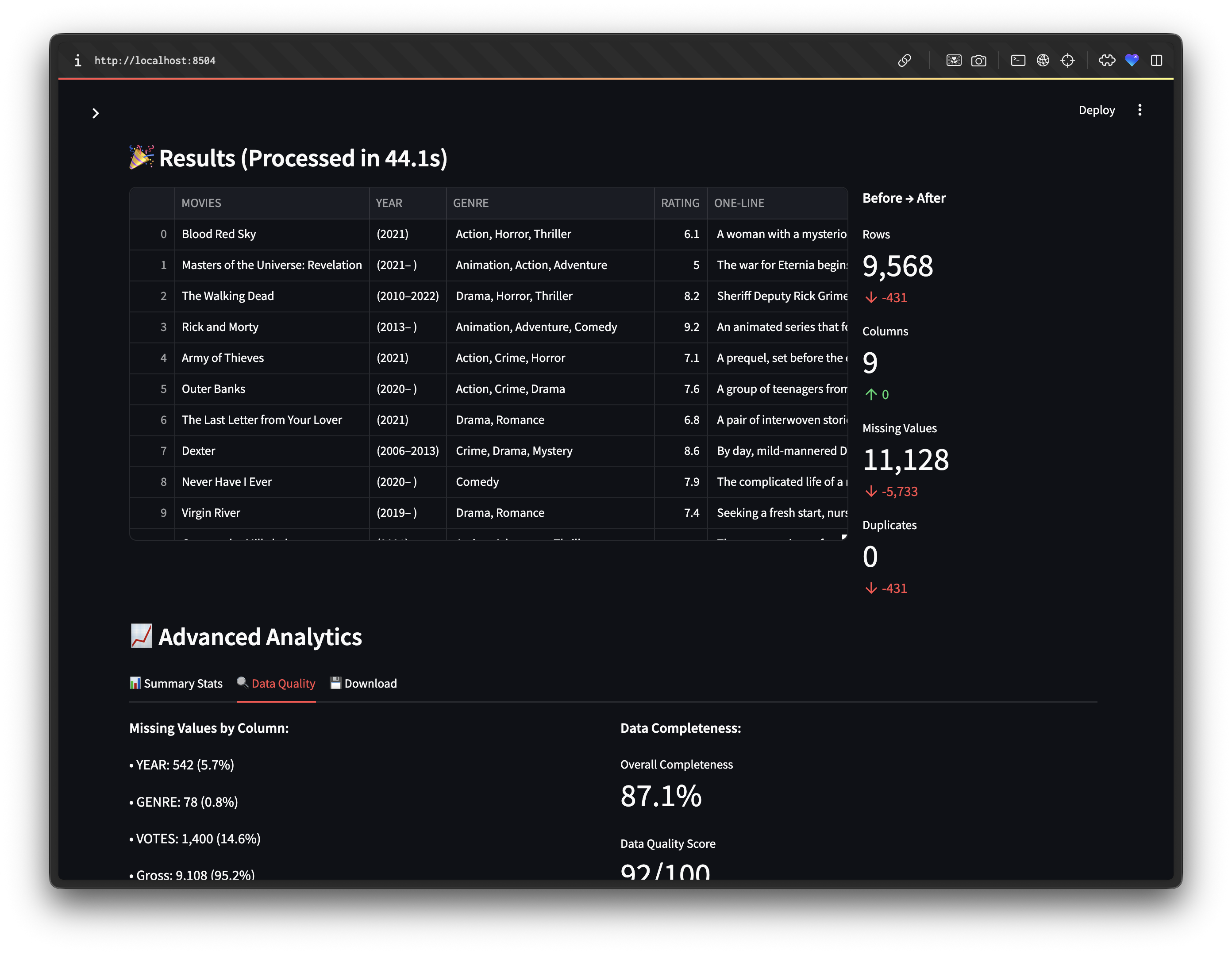
Application Code
Below is the full application code for the Data Preprocessor Agent System. You can expand the dropdown to view all code details.Show Application Code
Show Application Code
Copy
import streamlit as st
import pandas as pd
import requests
import re
import time
import json
from typing import Optional, Tuple, Dict, List
import numpy as np
from concurrent.futures import ThreadPoolExecutor, TimeoutError as FutureTimeoutError
# Configuration
GRAVIX_API_KEY = "" # GET YOUR API KEY FROM platform.gravixlayer.com
GRAVIX_ENDPOINT = "https://api.gravixlayer.com/v1/inference/chat/completions"
st.set_page_config(page_title="Enhanced 3-Agent Dataset Cleaner", layout="wide")
st.title("🤖 Enhanced Data Preprocessor Agent System")
class EnhancedAgent:
def __init__(self, name: str, role: str, system_prompt: str = ""):
self.name = name
self.role = role
self.system_prompt = system_prompt
self.success_count = 0
self.failure_count = 0
def call_llm(self, prompt: str, max_retries: int = 5, timeout: int = 60) -> Optional[str]:
"""Fixed LLM call with proper API handling for GravixLayer"""
# Simplify and clean the prompt
clean_prompt = self._clean_prompt(prompt)
for attempt in range(max_retries):
try:
headers = {
"Authorization": f"Bearer {GRAVIX_API_KEY}",
"Content-Type": "application/json",
"Accept": "application/json"
}
# Optimized payload for better success
payload = {
"model": "meta-llama/llama-3.1-8b-instruct",
"messages": [
{"role": "system", "content": self.system_prompt or "You are a helpful data processing assistant."},
{"role": "user", "content": clean_prompt}
],
"max_tokens": 1500, # More generous token limit
"temperature": 0.2, # Slightly more creative
"top_p": 0.9,
"frequency_penalty": 0.1,
"presence_penalty": 0.1
}
st.info(f"{self.name}: Attempt {attempt + 1}/{max_retries}...")
response = requests.post(
GRAVIX_ENDPOINT,
headers=headers,
json=payload,
timeout=timeout
)
# Debug response
st.info(f"API Response Status: {response.status_code}")
if response.status_code == 200:
try:
result = response.json()
# Debug the response structure
if "choices" in result and len(result["choices"]) > 0:
content = result["choices"][0]["message"]["content"]
if content and len(content.strip()) > 5:
self.success_count += 1
st.success(f"{self.name}: ✅ Got response ({len(content)} chars)!")
return content.strip()
else:
st.warning(f"{self.name}: Empty or very short response: '{content}'")
raise ValueError(f"Response too short: {len(content) if content else 0} chars")
else:
st.error(f"{self.name}: Invalid response structure: {result}")
raise ValueError("Invalid response structure")
except json.JSONDecodeError as e:
st.error(f"{self.name}: JSON decode error: {e}")
elif response.status_code == 429:
wait_time = (attempt + 1) * 10 # Progressive backoff for rate limits
st.warning(f"{self.name}: Rate limited. Waiting {wait_time}s...")
time.sleep(wait_time)
continue
elif response.status_code in [500, 502, 503, 504]:
wait_time = (attempt + 1) * 5
st.warning(f"{self.name}: Server error {response.status_code}. Waiting {wait_time}s...")
time.sleep(wait_time)
continue
else:
st.error(f"{self.name}: HTTP {response.status_code}: {response.text[:200]}")
raise requests.exceptions.HTTPError(f"HTTP {response.status_code}")
except requests.exceptions.Timeout:
if attempt < max_retries - 1:
st.warning(f"{self.name}: Timeout. Retrying...")
time.sleep(3)
continue
else:
st.error(f"{self.name}: Final timeout")
except Exception as e:
st.error(f"{self.name}: Unexpected error: {str(e)}")
if attempt == max_retries - 1:
break
time.sleep(2)
continue
self.failure_count += 1
st.error(f"{self.name}: ❌ All {max_retries} attempts failed")
return None
def _clean_prompt(self, prompt: str) -> str:
clean = re.sub(r'\s+', ' ', prompt)
# Ensure reasonable length
if len(clean) > 2000:
clean = clean[:2000] + "..."
return clean
def get_stats(self) -> Dict:
total = self.success_count + self.failure_count
return {
"success_rate": self.success_count / total if total > 0 else 0,
"total_calls": total
}
class SmartAnalystAgent(EnhancedAgent):
def __init__(self):
system_prompt = "You are a data cleaning expert. Analyze datasets and create practical cleaning strategies. Always provide specific, actionable recommendations."
super().__init__("🔬 Smart Analyst", "Advanced data analysis and strategy", system_prompt)
def quick_analysis(self, df: pd.DataFrame) -> Dict:
"""Enhanced analysis with better insights"""
analysis = {
'memory_usage': df.memory_usage(deep=True).sum(),
}
# Missing value analysis
missing_info = {}
for col in df.columns:
missing_count = df[col].isnull().sum()
if missing_count > 0:
missing_info[col] = {
'count': int(missing_count),
'percentage': round(missing_count / len(df) * 100, 2)
}
analysis['missing_analysis'] = missing_info
# Data quality issues
issues = []
duplicates = df.duplicated().sum()
# Check for potential categorical columns with high cardinality
for col in df.select_dtypes(include=['object']).columns:
unique_count = df[col].nunique()
total_count = len(df)
if unique_count > total_count * 0.8:
issues.append(f"'{col}' has high cardinality ({unique_count:,} unique values)")
# Check for potential date columns
date_candidates = []
for col in df.select_dtypes(include=['object']).columns:
if len(df) > 0:
sample = df[col].dropna().head(10).astype(str)
date_patterns = [
r'\d{4}[-/]\d{1,2}[-/]\d{1,2}',
r'\d{1,2}[-/]\d{1,2}[-/]\d{4}',
r'\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}'
]
if any(any(re.search(pattern, str(val)) for pattern in date_patterns) for val in sample):
date_candidates.append(col)
if date_candidates:
issues.append(f"Potential date columns: {', '.join(date_candidates)}")
analysis['issues'] = issues
analysis['date_candidates'] = date_candidates
analysis['priority_score'] = self._calculate_priority_score(analysis)
return analysis
def _calculate_priority_score(self, analysis: Dict) -> int:
"""Calculate cleaning priority based on data quality issues"""
score = 0
if analysis['missing_analysis']:
score += len(analysis['missing_analysis']) * 2
if 'duplicate' in ' '.join(analysis['issues']).lower():
score += 3
if 'date' in ' '.join(analysis['issues']).lower():
score += 1
return min(score, 10)
def create_cleaning_strategy(self, analysis: Dict) -> str:
"""Create optimized cleaning strategy with very simple prompts"""
# Create a very focused, simple prompt
missing_count = len(analysis['missing_analysis'])
has_duplicates = any('duplicate' in issue.lower() for issue in analysis['issues'])
has_dates = len(analysis.get('date_candidates', [])) > 0
prompt = f"""Create a data cleaning plan for a dataset with {analysis['shape'][0]} rows and {analysis['shape'][1]} columns.
Issues found:
- Missing data in {missing_count} columns
- Duplicates: {'Yes' if has_duplicates else 'No'}
- Date columns to fix: {'Yes' if has_dates else 'No'}
Write a numbered cleaning plan with 4-5 specific steps. Be direct and practical."""
return self.call_llm(prompt)
class SmartCoderAgent(EnhancedAgent):
def __init__(self):
system_prompt = "You are a Python expert specializing in pandas data cleaning. Generate clean, working code that handles missing values, duplicates, and data type issues. Always include proper error handling."
super().__init__("⚙️ Smart Coder", "Advanced code generation", system_prompt)
def generate_cleaning_code(self, analysis: Dict, strategy: str) -> str:
"""Generate optimized cleaning code with very simple prompts"""
# Create simple, focused prompt
prompt = f"""Write a Python function called clean_dataset(df) that cleans a pandas DataFrame.
The dataset has:
- {analysis['shape'][0]} rows and {analysis['shape'][1]} columns
- Missing values in {len(analysis['missing_analysis'])} columns
- {"Duplicates present" if any('duplicate' in issue.lower() for issue in analysis['issues']) else "No duplicates"}
Strategy: {strategy[:300] if strategy else 'Standard cleaning'}
Requirements:
1. Remove duplicates if any
2. Fill missing numeric values with median
3. Fill missing text values with mode or 'Unknown'
4. Convert date columns if detected
5. Return the cleaned DataFrame
Write only the Python function code, nothing else."""
return self.call_llm(prompt)
class SmartValidatorAgent(EnhancedAgent):
def __init__(self):
system_prompt = """You are a code testing and debugging expert. Fix Python code efficiently.
Focus on common pandas issues and provide robust solutions."""
super().__init__("✅ Smart Validator", "Code testing and fixing", system_prompt)
def validate_and_fix(self, code: str, df: pd.DataFrame, max_fixes: int = 2) -> Tuple[bool, str, Optional[pd.DataFrame]]:
"""Enhanced validation with intelligent fixing"""
for fix_attempt in range(max_fixes + 1):
if fix_attempt == 0:
current_code = code
st.info(f"{self.name}: Testing generated code...")
else:
st.info(f"{self.name}: Attempting fix #{fix_attempt}...")
success, message, result = self._test_code(current_code, df)
if success:
return True, message, result
if fix_attempt < max_fixes:
# Try to fix the code
current_code = self._fix_code(current_code, message, df)
if not current_code:
break
return False, f"Could not fix code after {max_fixes} attempts", None
def _test_code(self, code: str, df: pd.DataFrame) -> Tuple[bool, str, Optional[pd.DataFrame]]:
"""Test code execution"""
try:
cleaned_code = self._clean_code_format(code)
if not cleaned_code or 'def clean_dataset' not in cleaned_code:
return False, "Invalid function format", None
# Test compilation
compile(cleaned_code, '<string>', 'exec')
# Execute in safe environment
safe_globals = {
'pd': pd, 'np': np, 'df': df.copy(),
're': re, 'datetime': __import__('datetime')
}
exec(cleaned_code, safe_globals)
if 'clean_dataset' not in safe_globals:
return False, "Function clean_dataset not found", None
# Test the function
test_df = df.copy()
result = safe_globals['clean_dataset'](test_df)
if result is None:
return False, "Function returned None", None
if not isinstance(result, pd.DataFrame):
return False, f"Expected DataFrame, got {type(result)}", None
if result.empty and not df.empty:
return False, "Function returned empty DataFrame", None
return True, f"Success! Cleaned {len(df)} → {len(result)} rows", result
except Exception as e:
return False, f"Execution error: {str(e)}", None
def _fix_code(self, broken_code: str, error: str, df: pd.DataFrame) -> Optional[str]:
"""Fix broken code using LLM"""
sample_columns = list(df.columns)[:10]
prompt = f"""
Fix this broken Python function:
**Broken Code:**
{broken_code[:800]}
**Error:** {error}
**Dataset Context:**
- Columns: {sample_columns}
- Shape: {df.shape}
**Common Issues to Fix:**
- Import statements
- Column name typos
- Data type issues
- Pandas method errors
Return ONLY the corrected function (no markdown).
"""
return self.call_llm(prompt, max_retries=1, timeout=20)
def _clean_code_format(self, code: str) -> str:
"""Clean and format code"""
if not code:
return ""
# Remove markdown
cleaned = re.sub(r'```(?:python)?\s*', '', code)
cleaned = re.sub(r'```\s*', '', cleaned)
cleaned = cleaned.strip()
# Ensure imports
required_imports = ['import pandas as pd', 'import numpy as np']
for imp in required_imports:
if imp.split()[-1] in cleaned and imp not in cleaned:
cleaned = imp + '\n' + cleaned
return cleaned
def advanced_fallback_cleaning(df: pd.DataFrame) -> pd.DataFrame:
"""Enhanced intelligent fallback with detailed progress"""
st.info("🧠 Activating Advanced AI Fallback Cleaning...")
progress_bar = st.progress(0)
status_text = st.empty()
try:
cleaned_df = df.copy()
operations = []
# Phase 1: Data Quality Assessment
status_text.text("Phase 1: Analyzing data quality...")
progress_bar.progress(15)
original_shape = cleaned_df.shape
missing_before = cleaned_df.isnull().sum().sum()
duplicates_before = cleaned_df.duplicated().sum()
# Phase 2: Handle Duplicates
status_text.text("Phase 2: Removing duplicates...")
progress_bar.progress(30)
if duplicates_before > 0:
cleaned_df = cleaned_df.drop_duplicates()
duplicates_removed = duplicates_before
operations.append(f"✅ Removed {duplicates_removed:,} duplicate rows")
st.success(operations[-1])
# Phase 3: Smart Column Analysis
status_text.text("Phase 3: Analyzing columns...")
progress_bar.progress(45)
columns_to_drop = []
for col in cleaned_df.columns:
missing_pct = cleaned_df[col].isnull().sum() / len(cleaned_df) if len(cleaned_df) > 0 else 0
unique_pct = cleaned_df[col].nunique() / len(cleaned_df) if len(cleaned_df) > 0 else 0
if missing_pct >= 0.9: # Drop if 90% missing
columns_to_drop.append(col)
elif unique_pct >= 0.95 and cleaned_df[col].dtype == 'object': # Likely ID columns
columns_to_drop.append(col)
if columns_to_drop:
cleaned_df = cleaned_df.drop(columns=columns_to_drop)
operations.append(f"🗑️ Dropped {len(columns_to_drop)} low-quality columns")
st.info(operations[-1])
# Phase 4: Intelligent Missing Value Handling
status_text.text("Phase 4: Handling missing values...")
progress_bar.progress(65)
for col in cleaned_df.columns:
missing_count = cleaned_df[col].isnull().sum()
if missing_count > 0:
if pd.api.types.is_numeric_dtype(cleaned_df[col]):
# Use median for skewed data, mean for normal
skewness = abs(cleaned_df[col].skew()) if not cleaned_df[col].dropna().empty else 0
if skewness > 1: # Highly skewed
fill_value = cleaned_df[col].median()
method = "median"
else:
fill_value = cleaned_df[col].mean()
method = "mean"
if pd.notna(fill_value):
cleaned_df[col] = cleaned_df[col].fillna(fill_value)
operations.append(f"🔢 Filled {missing_count:,} values in '{col}' with {method}")
elif cleaned_df[col].dtype == 'object':
# Smart categorical handling
mode_vals = cleaned_df[col].mode()
if len(mode_vals) > 0 and mode_vals[0] is not None:
cleaned_df[col] = cleaned_df[col].fillna(mode_vals[0])
operations.append(f"📝 Filled {missing_count:,} values in '{col}' with mode")
else:
cleaned_df[col] = cleaned_df[col].fillna('Unknown')
operations.append(f"❓ Filled {missing_count:,} values in '{col}' with 'Unknown'")
# Phase 5: Date Detection and Conversion
status_text.text("Phase 5: Converting date columns...")
progress_bar.progress(80)
for col in cleaned_df.select_dtypes(include=['object']).columns:
if len(cleaned_df) > 0:
sample = cleaned_df[col].dropna().head(50).astype(str)
# Advanced date pattern detection
date_patterns = [
r'\d{4}-\d{1,2}-\d{1,2}', # YYYY-MM-DD
r'\d{1,2}/\d{1,2}/\d{4}', # MM/DD/YYYY
r'\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}', # ISO format
]
date_matches = sum(1 for val in sample
for pattern in date_patterns
if re.search(pattern, str(val)))
if date_matches > len(sample) * 0.7: # 70% match threshold
try:
cleaned_df[col] = pd.to_datetime(cleaned_df[col], errors='coerce')
valid_dates = cleaned_df[col].notna().sum()
operations.append(f"📅 Converted '{col}' to datetime ({valid_dates:,} valid)")
st.success(operations[-1])
except:
pass
# Phase 6: Final Optimization
status_text.text("Phase 6: Final optimization...")
progress_bar.progress(95)
# Remove completely empty rows
empty_rows = cleaned_df.isnull().all(axis=1).sum()
if empty_rows > 0:
cleaned_df = cleaned_df.dropna(how='all')
operations.append(f"🧹 Removed {empty_rows} completely empty rows")
# Optimize data types
memory_before = cleaned_df.memory_usage(deep=True).sum()
for col in cleaned_df.select_dtypes(include=['int64']).columns:
if cleaned_df[col].min() >= 0 and cleaned_df[col].max() <= 255:
cleaned_df[col] = cleaned_df[col].astype('uint8')
elif cleaned_df[col].min() >= -32768 and cleaned_df[col].max() <= 32767:
cleaned_df[col] = cleaned_df[col].astype('int16')
memory_after = cleaned_df.memory_usage(deep=True).sum()
memory_saved = memory_before - memory_after
if memory_saved > 0:
operations.append(f"💾 Optimized memory usage (saved {memory_saved/1024/1024:.1f} MB)")
# Completion
progress_bar.progress(100)
status_text.text("✅ Advanced cleaning completed!")
# Final summary
missing_after = cleaned_df.isnull().sum().sum()
st.success(f"""
🎉 **Advanced AI Cleaning Complete!**
- Original: {original_shape[0]:,} rows × {original_shape[1]} columns
- Final: {cleaned_df.shape[0]:,} rows × {cleaned_df.shape[1]} columns
- Missing values: {missing_before:,} → {missing_after:,}
- Operations performed: {len(operations)}
""")
# Show operations
with st.expander("📋 Cleaning Operations Performed"):
for op in operations:
st.write(op)
time.sleep(1)
progress_bar.empty()
status_text.empty()
return cleaned_df
except Exception as e:
st.error(f"Advanced fallback failed: {e}")
progress_bar.empty()
status_text.empty()
return df
def display_agent_stats(agents: List[EnhancedAgent]):
"""Display agent performance statistics"""
st.subheader("🤖 Agent Performance")
cols = st.columns(len(agents))
for i, agent in enumerate(agents):
with cols[i]:
stats = agent.get_stats()
st.metric(
label=agent.name,
value=f"{stats['success_rate']:.1%}",
delta=f"{stats['total_calls']} calls"
)
def main():
# Initialize enhanced agents
analyst = SmartAnalystAgent()
coder = SmartCoderAgent()
validator = SmartValidatorAgent()
# Sidebar configuration
with st.sidebar:
st.header("⚙️ Configuration")
use_parallel = st.checkbox("Parallel Processing", value=True,
help="Process some operations in parallel for speed")
max_retries = st.slider("Max Retries per Agent", 1, 5, 2)
st.header("📊 System Status")
display_agent_stats([analyst, coder, validator])
# Main interface
uploaded_file = st.file_uploader(
"Upload your dataset",
type=["csv", "xlsx"],
help="Supports CSV and Excel files up to 200MB"
)
if uploaded_file:
# Load data with better error handling
try:
if uploaded_file.name.endswith('.csv'):
# Try different encodings
for encoding in ['utf-8', 'latin1', 'cp1252']:
try:
df = pd.read_csv(uploaded_file, encoding=encoding)
st.success(f"✅ Loaded CSV with {encoding} encoding")
break
except UnicodeDecodeError:
continue
else:
raise ValueError("Could not decode CSV with any standard encoding")
elif uploaded_file.name.endswith('.xlsx'):
df = pd.read_excel(uploaded_file)
st.success("✅ Loaded Excel file")
except Exception as e:
st.error(f"❌ Failed to load file: {e}")
return
# Dataset overview
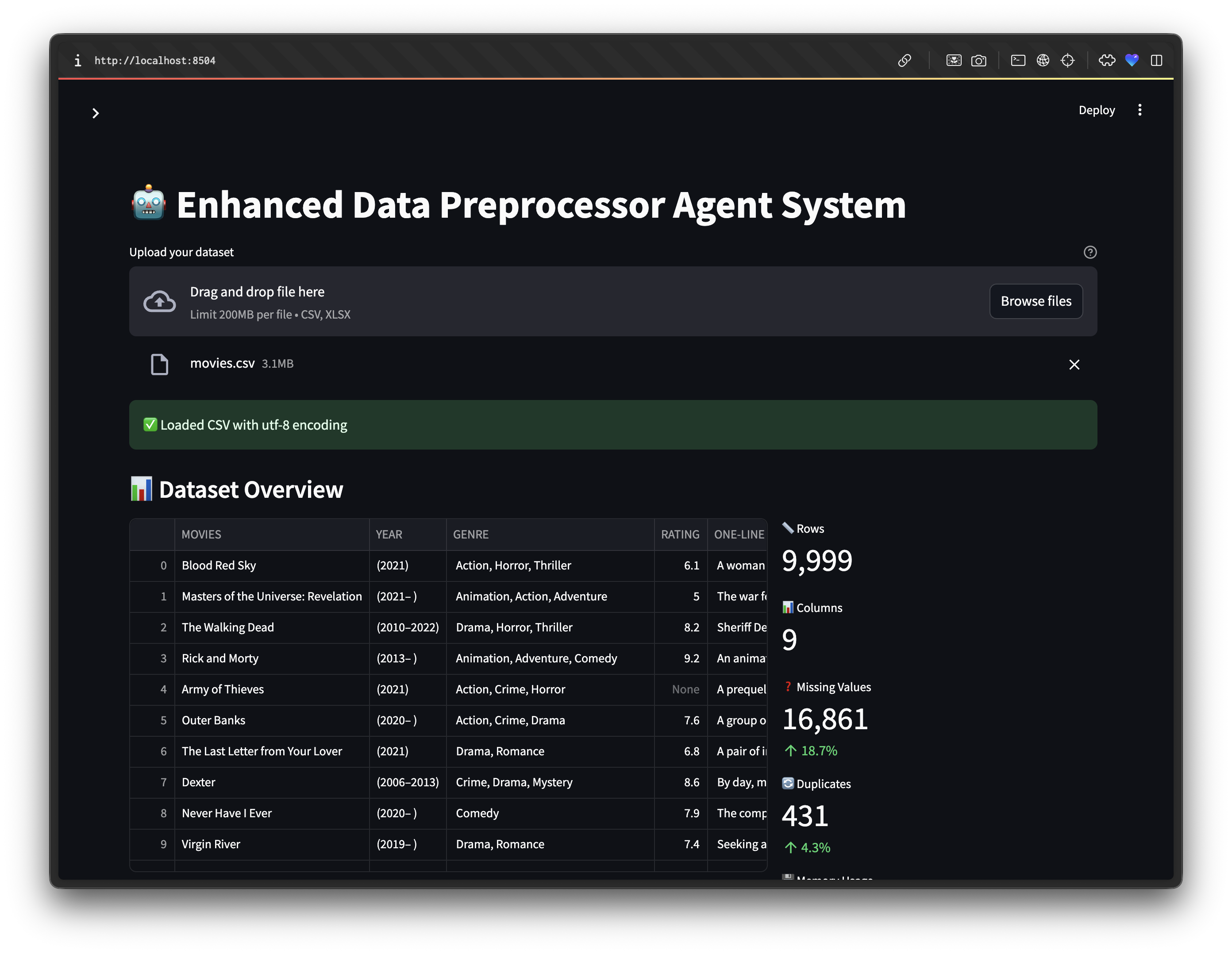
st.subheader("📊 Dataset Overview")
col1, col2 = st.columns([2, 1])
with col1:
try:
st.dataframe(df.head(10), height=400)
except:
st.info(f"Dataset preview unavailable. Shape: {df.shape}")
with col2:
# Enhanced metrics
st.metric("📏 Rows", f"{df.shape[0]:,}")
st.metric("📊 Columns", f"{df.shape[1]}")
missing_total = df.isnull().sum().sum()
missing_pct = (missing_total / df.size * 100) if df.size > 0 else 0
st.metric("❓ Missing Values", f"{missing_total:,}", f"{missing_pct:.1f}%")
duplicates = df.duplicated().sum()
dup_pct = (duplicates / len(df) * 100) if len(df) > 0 else 0
st.metric("🔄 Duplicates", f"{duplicates:,}", f"{dup_pct:.1f}%")
memory_mb = df.memory_usage(deep=True).sum() / 1024 / 1024
st.metric("💾 Memory Usage", f"{memory_mb:.1f} MB")
# Quick data quality assessment
with st.expander("🔍 Quick Data Quality Check"):
col1, col2 = st.columns(2)
with col1:
st.write("**Column Types:**")
type_counts = df.dtypes.value_counts()
for dtype, count in type_counts.items():
st.write(f"• {dtype}: {count} columns")
with col2:
st.write("**Missing Value Summary:**")
missing_by_col = df.isnull().sum()
missing_cols = missing_by_col[missing_by_col > 0].head(5)
if missing_cols.empty:
st.success("No missing values detected! ✅")
else:
for col, count in missing_cols.items():
pct = (count / len(df) * 100)
st.write(f"• {col}: {count:,} ({pct:.1f}%)")
# Main cleaning button
if st.button("🚀 Start Enhanced Cleaning", type="primary", use_container_width=True):
start_time = time.time()
overall_progress = st.progress(0)
main_status = st.empty()
try:
# Phase 1: Analysis
main_status.info("🔬 Phase 1: Intelligent Analysis")
overall_progress.progress(20)
analysis = analyst.quick_analysis(df)
with st.expander("📋 Analysis Results"):
col1, col2 = st.columns(2)
with col1:
st.write("**Key Issues:**")
for issue in analysis['issues'][:5]:
st.write(f"• {issue}")
with col2:
st.write(f"**Priority Score:** {analysis['priority_score']}/10")
st.write(f"**Columns with Missing Data:** {len(analysis['missing_analysis'])}")
if analysis['date_candidates']:
st.write(f"**Date Candidates:** {', '.join(analysis['date_candidates'])}")
# Phase 2: Strategy
main_status.info("🎯 Phase 2: Creating Cleaning Strategy")
overall_progress.progress(40)
strategy = analyst.create_cleaning_strategy(analysis)
if not strategy:
st.error("❌ Strategy creation completely failed. Cannot proceed without AI agents working.")
st.info("💡 Check your API key or try again. The AI agents must work for this system to function.")
return
else:
with st.expander("📝 Cleaning Strategy"):
st.write(strategy)
# Phase 3: Code Generation
main_status.info("⚙️ Phase 3: Generating Smart Code")
overall_progress.progress(60)
code = coder.generate_cleaning_code(analysis, strategy)
if not code:
st.error("❌ Code generation completely failed. AI agents are not responding properly.")
st.info("💡 This means there's an issue with the API connection or configuration.")
return
else:
# Phase 4: Validation & Execution
main_status.info("✅ Phase 4: Testing & Validation")
overall_progress.progress(80)
success, message, result_df = validator.validate_and_fix(code, df)
if success:
cleaned_df = result_df
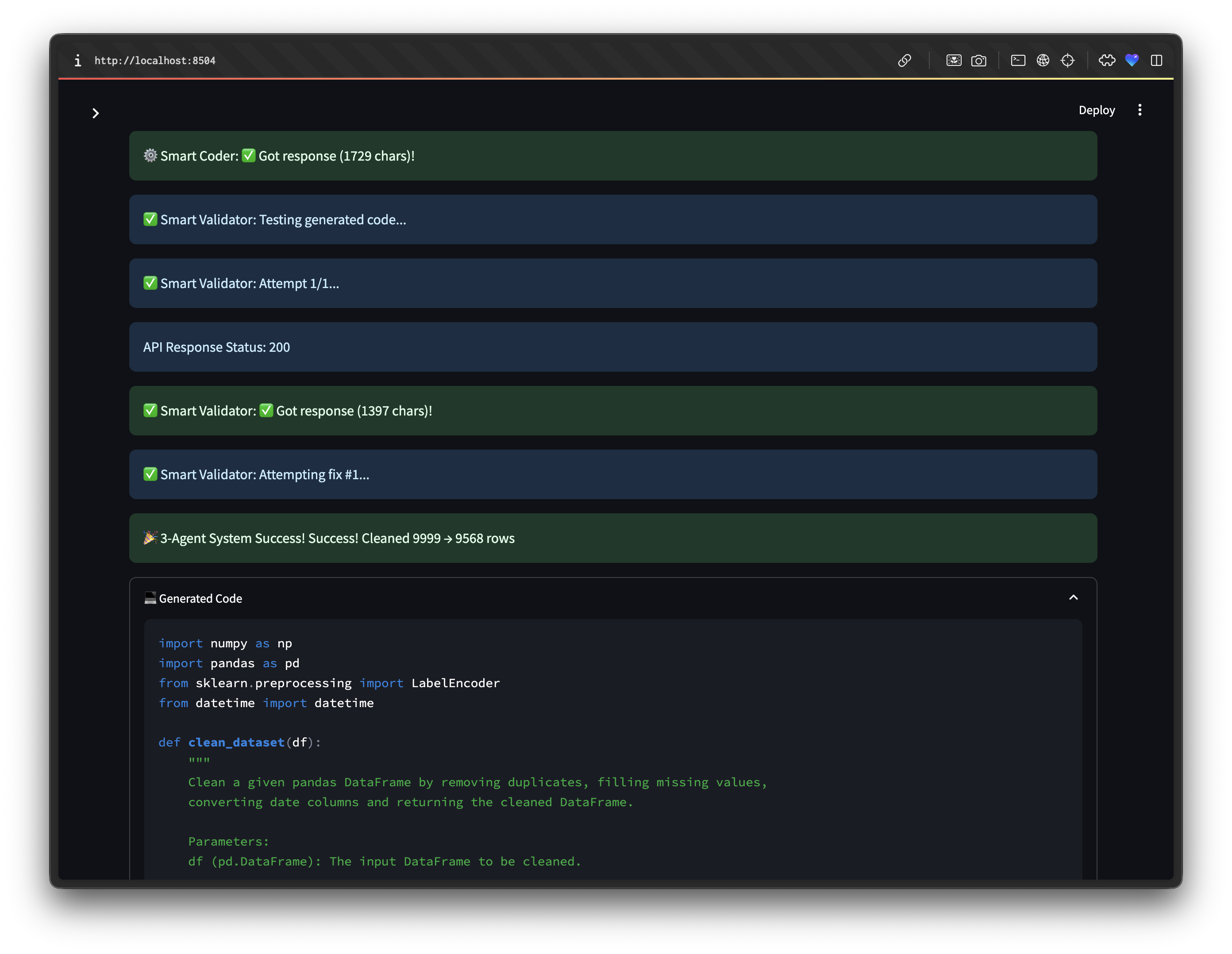
st.success(f"🎉 3-Agent System Success! {message}")
with st.expander("💻 Generated Code"):
st.code(validator._clean_code_format(code), language="python")
else:
st.error(f"❌ Validation failed: {message}")
st.info("💡 The AI agents are working but generated code has issues. This is a code quality problem, not an API problem.")
return
# Results Display
main_status.success("✅ Cleaning Complete!")
overall_progress.progress(100)
processing_time = time.time() - start_time
st.subheader(f"🎉 Results (Processed in {processing_time:.1f}s)")
# Enhanced results display
col1, col2 = st.columns([3, 1])
with col1:
try:
st.dataframe(cleaned_df.head(15), height=400)
except:
st.info(f"Cleaned dataset ready. Shape: {cleaned_df.shape}")
with col2:
# Comparison metrics
st.write("**Before → After**")
st.metric("Rows",
f"{cleaned_df.shape[0]:,}",
f"{cleaned_df.shape[0] - df.shape[0]:,}")
st.metric("Columns",
cleaned_df.shape[1],
cleaned_df.shape[1] - df.shape[1])
missing_after = cleaned_df.isnull().sum().sum()
missing_before = df.isnull().sum().sum()
st.metric("Missing Values",
f"{missing_after:,}",
f"{missing_after - missing_before:,}")
dup_after = cleaned_df.duplicated().sum()
dup_before = df.duplicated().sum()
st.metric("Duplicates",
f"{dup_after:,}",
f"{dup_after - dup_before:,}")
# Advanced Analytics
st.subheader("📈 Advanced Analytics")
tab1, tab2, tab3 = st.tabs(["📊 Summary Stats", "🔍 Data Quality", "💾 Download"])
with tab1:
col1, col2 = st.columns(2)
with col1:
st.write("**Data Types Distribution:**")
type_dist = cleaned_df.dtypes.value_counts()
for dtype, count in type_dist.items():
st.write(f"• {dtype}: {count} columns")
with col2:
st.write("**Numeric Summary:**")
numeric_cols = cleaned_df.select_dtypes(include=[np.number]).columns
if len(numeric_cols) > 0:
st.dataframe(cleaned_df[numeric_cols].describe().round(2))
else:
st.info("No numeric columns found")
with tab2:
col1, col2 = st.columns(2)
with col1:
st.write("**Missing Values by Column:**")
missing_summary = cleaned_df.isnull().sum()
missing_cols = missing_summary[missing_summary > 0]
if missing_cols.empty:
st.success("✅ No missing values!")
else:
for col, count in missing_cols.items():
pct = (count / len(cleaned_df) * 100)
st.write(f"• {col}: {count:,} ({pct:.1f}%)")
with col2:
st.write("**Data Completeness:**")
total_cells = cleaned_df.size
filled_cells = total_cells - cleaned_df.isnull().sum().sum()
completeness = (filled_cells / total_cells * 100) if total_cells > 0 else 100
st.metric("Overall Completeness", f"{completeness:.1f}%")
# Quality score
quality_factors = {
'completeness': completeness / 100,
'no_duplicates': 1 - (dup_after / len(cleaned_df)) if len(cleaned_df) > 0 else 1,
'data_consistency': 0.9 # Placeholder for consistency check
}
overall_quality = sum(quality_factors.values()) / len(quality_factors) * 100
st.metric("Data Quality Score", f"{overall_quality:.0f}/100")
with tab3:
st.write("**Export Options:**")
# CSV download
csv_data = cleaned_df.to_csv(index=False)
st.download_button(
label="📥 Download as CSV",
data=csv_data,
file_name=f"enhanced_cleaned_{uploaded_file.name.split('.')[0]}.csv",
mime="text/csv",
use_container_width=True
)
# Excel download (if original was Excel)
if uploaded_file.name.endswith('.xlsx'):
try:
from io import BytesIO
excel_buffer = BytesIO()
cleaned_df.to_excel(excel_buffer, index=False, engine='openpyxl')
excel_data = excel_buffer.getvalue()
st.download_button(
label="📊 Download as Excel",
data=excel_data,
file_name=f"enhanced_cleaned_{uploaded_file.name}",
mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
use_container_width=True
)
except ImportError:
st.info("Excel export requires openpyxl package")
# Summary report
summary_report = f"""# Data Cleaning Report
## Original Dataset
- **File:** {uploaded_file.name}
- **Shape:** {df.shape[0]:,} rows × {df.shape[1]} columns
- **Missing Values:** {missing_before:,}
- **Duplicates:** {dup_before:,}
- **Processing Time:** {processing_time:.1f} seconds
## Cleaned Dataset
- **Shape:** {cleaned_df.shape[0]:,} rows × {cleaned_df.shape[1]} columns
- **Missing Values:** {missing_after:,} (Δ {missing_after - missing_before:,})
- **Duplicates:** {dup_after:,} (Δ {dup_after - dup_before:,})
- **Data Quality Score:** {overall_quality:.0f}/100
## Agent Performance
- **Analyst:** {analyst.get_stats()['success_rate']:.1%} success rate
- **Coder:** {coder.get_stats()['success_rate']:.1%} success rate
- **Validator:** {validator.get_stats()['success_rate']:.1%} success rate
## Data Types
{cleaned_df.dtypes.value_counts().to_string()}
Generated by Enhanced 3-Agent Dataset Cleaner
"""
st.download_button(
label="📋 Download Cleaning Report",
data=summary_report,
file_name=f"cleaning_report_{uploaded_file.name.split('.')[0]}.md",
mime="text/markdown",
use_container_width=True
)
# Cleanup
time.sleep(1)
overall_progress.empty()
main_status.empty()
except Exception as e:
st.error(f"❌ Unexpected error during processing: {str(e)}")
st.info("Please try uploading your file again or contact support.")
overall_progress.empty()
main_status.empty()
else:
# Landing page content
st.markdown("""
## 🌟 Welcome to the Enhanced 3-Agent Dataset Cleaner!
This advanced system uses three specialized AI agents to automatically clean and optimize your datasets:
### 🤖 Meet Your AI Team:
**🔬 Smart Analyst Agent**
- Performs comprehensive data quality analysis
- Identifies patterns, anomalies, and cleaning priorities
- Creates intelligent cleaning strategies
**⚙️ Smart Coder Agent**
- Generates optimized Python cleaning code
- Handles complex data transformations
- Includes robust error handling and validation
**✅ Smart Validator Agent**
- Tests and validates generated code
- Automatically fixes common issues
- Ensures data integrity throughout the process
### ✨ Key Features:
- **Intelligent Missing Value Handling**: Smart imputation based on data patterns
- **Advanced Duplicate Detection**: Removes redundant rows while preserving data integrity
- **Automatic Date Recognition**: Converts date strings to proper datetime format
- **Memory Optimization**: Reduces dataset memory footprint
- **Parallel Processing**: Faster execution with multi-threading
- **Comprehensive Reporting**: Detailed cleaning reports and quality metrics
- **Multiple Export Formats**: CSV, Excel, and detailed reports
### 🚀 How It Works:
1. **Upload** your CSV or Excel file
2. **Analyze** - The system examines your data quality
3. **Strategy** - Creates a customized cleaning plan
4. **Execute** - Generates and runs cleaning code
5. **Validate** - Ensures results meet quality standards
6. **Download** - Get your cleaned dataset and reports
### 📊 Supported File Types:
- CSV files (UTF-8, Latin1, CP1252 encodings)
- Excel files (.xlsx)
- Files up to 200MB
**Ready to clean your data? Upload a file to get started!** 🎯
""")
# Sample datasets or demo section
with st.expander("🎮 Try with Sample Data"):
st.write("Want to test the system? Here are some sample scenarios:")
if st.button("Generate Sample Messy Dataset"):
# Create a sample messy dataset for demonstration
np.random.seed(42)
sample_data = {
'id': range(1, 101),
'name': ['User_' + str(i) if i % 10 != 0 else None for i in range(1, 101)],
'email': [f'user{i}@email.com' if i % 15 != 0 else None for i in range(1, 101)],
'age': [np.random.randint(18, 80) if i % 8 != 0 else None for i in range(1, 101)],
'salary': [np.random.randint(30000, 120000) if i % 12 != 0 else None for i in range(1, 101)],
'date_joined': [f'2023-{np.random.randint(1,13):02d}-{np.random.randint(1,28):02d}' if i % 7 != 0 else None for i in range(1, 101)],
'department': [np.random.choice(['Sales', 'Engineering', 'HR', 'Marketing']) if i % 6 != 0 else None for i in range(1, 101)]
}
# Add some duplicates
sample_df = pd.DataFrame(sample_data)
duplicates = sample_df.iloc[:5].copy() # Add 5 duplicate rows
sample_df = pd.concat([sample_df, duplicates], ignore_index=True)
st.success("✅ Sample dataset generated!")
st.dataframe(sample_df.head(10))
# Download sample
csv_sample = sample_df.to_csv(index=False)
st.download_button(
label="📥 Download Sample Dataset",
data=csv_sample,
file_name="sample_messy_dataset.csv",
mime="text/csv"
)
if __name__ == "__main__":
main()