WebSearch-LLM: Adding Web Search to LLMs
Introduction
WebSearch-LLM is an open-source project designed to enhance Large Language Models (LLMs) by integrating real-time web search capabilities. It acts as an OpenAI-compatible proxy server that allows LLMs to access live information from the web, overcoming the limitations of static training data. This guide, built for Gravix Layer, demonstrates how to combine LLM reasoning with dynamic web data retrieval.
The core idea is to provide LLMs with a "web_search" tool that fetches search results from DuckDuckGo (with fallbacks to Wikipedia and DuckDuckGo's Instant Answer API). The results are structured (including title, URL, and snippet) and fed back to the LLM for synthesis into coherent answers with citations. This makes LLMs more practical for time-sensitive or factual queries.
Key features:
- OpenAI Compatibility: Mirrors the OpenAI Chat Completions API, making it easy to integrate into existing applications.
- Tool-Calling Support: Works with models that support function/tool calling, but includes fallbacks for those that don't.
- Fallback Mechanisms: Ensures reliability by using multiple search providers if the primary one fails.
- Citation and Synthesis: Encourages the LLM to cite sources and synthesize responses based on search results.
- No Hard Dependencies: Uses lightweight libraries and avoids requiring API keys for search (though Gravix Layer API key is needed for LLM inference).
This project is ideal for developers building AI assistants that need up-to-date information, such as chatbots, research tools, or question-answering systems.
GitHub Repository
You can find the full source code for WebSearch-LLM on GitHub: Gravixlayer/guides: WebSearch-LLM
This repository contains:
- The WebSearch-LLM proxy server and tools
- Example clients and usage guides
- Documentation and setup instructions
Feel free to star, fork, or open issues and pull requests to contribute or ask questions!
How It Works
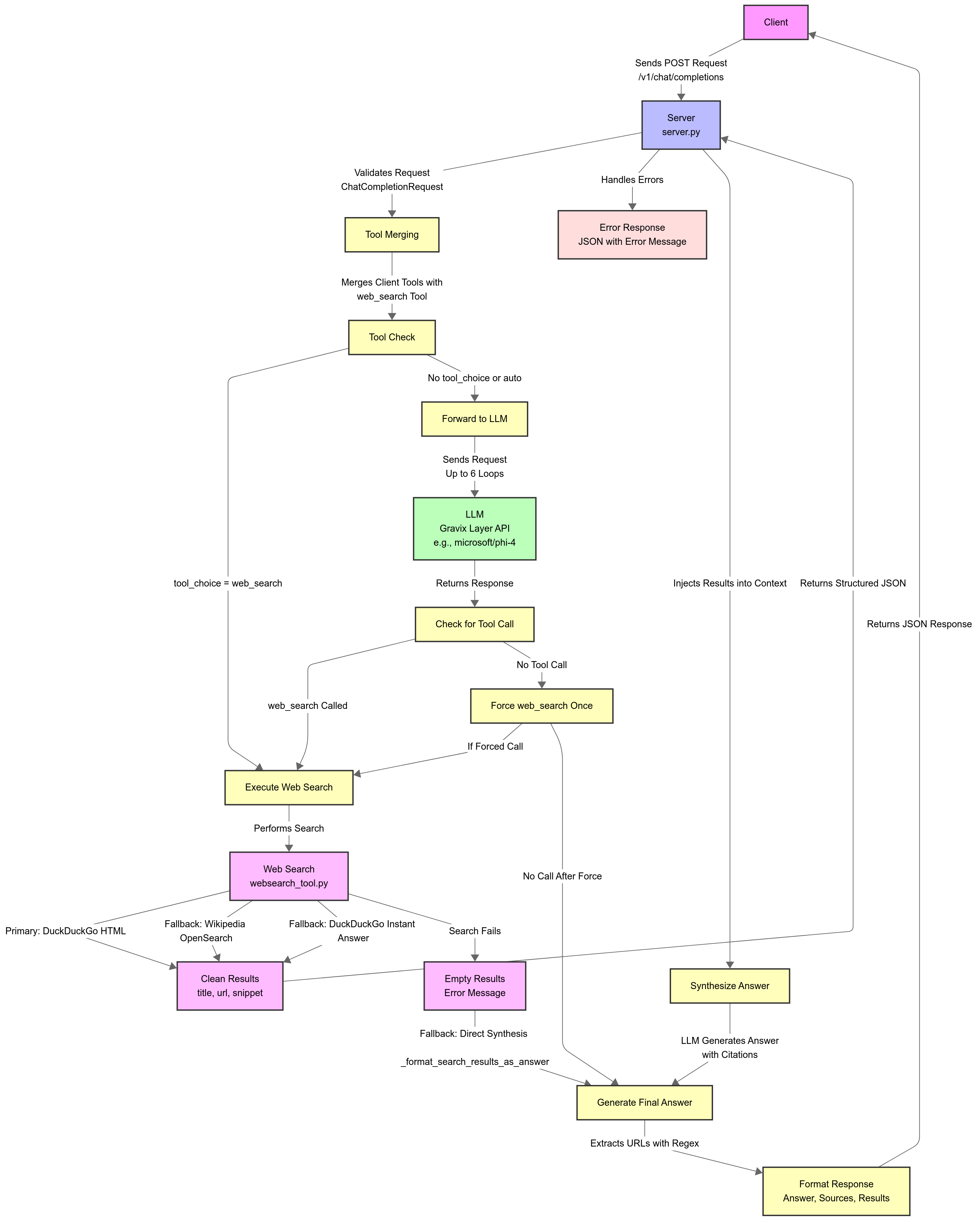
The system operates as a proxy between a client (e.g., your application) and an LLM backend (via Gravix Layer's API). Here's a step-by-step breakdown:
-
Client Sends Request: The client makes a POST request to the proxy server's
/v1/chat/completionsendpoint in OpenAI format. This includes messages (system prompt, user query), optional tools, and parameters like temperature. -
Tool Merging: The server merges any client-provided tools with its built-in
web_searchtool. This ensures the web search functionality is always available without duplication. -
Tool Execution Check:
- If the request forces a tool call (via
tool_choice), the server immediately executes theweb_searchtool if specified. - Otherwise, the server forwards the request to the LLM (e.g., microsoft/phi-4 or llama3.1:8b).
- If the LLM decides to call the
web_searchtool (based on the query), the server intercepts it.
- If the request forces a tool call (via
-
Web Search Execution:
- The server performs a search using DuckDuckGo's HTML scraping for rich results.
- Fallbacks: If DuckDuckGo fails, it tries Wikipedia's OpenSearch API or DuckDuckGo's Instant Answer API.
- Results are parsed into a list of dictionaries with
title,url, andsnippet. Duplicates are removed, and snippets are cleaned (e.g., removing boilerplate text).
-
Injection into LLM Context:
- Search results are added to the conversation history as a "tool" response.
- The LLM is prompted to synthesize an answer using only these results, citing URLs.
-
Response Generation:
- The LLM generates a final answer.
- The server extracts sources (URLs) from the response using regex patterns (e.g., markdown links, plain URLs).
- The response is returned in OpenAI format, including the answer, sources, and raw search results.
-
Fallback for Non-Tool Models: If the LLM doesn't support tools or fails to call them, the server runs a direct search and formats a synthesized answer without LLM involvement.
This workflow ensures the LLM always has access to fresh data while maintaining efficiency (up to 6 tool-call loops to prevent infinite loops).
Architecture
The project consists of several key files, each serving a specific role:
1. server.py (FastAPI Server)
- Purpose: Handles incoming requests, manages tool calls, and orchestrates interactions between the client, LLM, and search tool.
- Key Components:
- FastAPI app with a single endpoint:
/v1/chat/completions. - Pydantic model (
ChatCompletionRequest) for validating request payloads. - Lazy import of OpenAI client to avoid import-time dependencies.
- Tool merging logic to combine client tools with built-in ones.
- Forced tool execution: If
tool_choicespecifiesweb_search, it runs the search immediately and synthesizes a response. - Tool-call loop: Up to 6 iterations to handle multiple tool calls.
- Fallback: Direct search if LLM fails.
- Response formatting: Includes synthesized answer, extracted sources, and raw results.
- FastAPI app with a single endpoint:
- Dependencies: FastAPI, Pydantic, Uvicorn.
2. websearch_tool.py (Search Logic and CLI Tool)
- Purpose: Defines the
web_searchtool schema and implements the search functionality. Also provides a standalone CLI for testing. - Key Components:
- Tool Schema: OpenAI-compatible function definition with parameters
query(required) andtop_k(default 5). - Search Function (
perform_web_search):- Primary: DuckDuckGo HTML scraping using BeautifulSoup to extract titles, URLs, and cleaned snippets.
- Secondary: Wikipedia OpenSearch API for encyclopedic results.
- Tertiary: DuckDuckGo Instant Answer API for quick facts.
- Handles errors gracefully and returns structured JSON.
- Chat Function (
chat_with_websearch): Standalone LLM chat with tool support, including forced calls and fallbacks. - Fallback Formatting (
_format_search_results_as_answer): Synthesizes a response with citations if no LLM is used. - CLI: Supports
--askfor tool-enabled chat or--searchfor direct JSON results.
- Tool Schema: OpenAI-compatible function definition with parameters
- Dependencies: requests, duckduckgo-search, beautifulsoup4.
3. test.py (Example Client)
- Purpose: Demonstrates how to interact with the server using a simple Python script.
- Key Components:
- Constructs an OpenAI-style payload with system prompt, user query, tools, and
tool_choiceto force web search. - Sends POST request to the server.
- Prints status code, raw response, and parsed JSON.
- Constructs an OpenAI-style payload with system prompt, user query, tools, and
- Usage: Run with
python test.pyto query "What is Gravix Layer?".
4. readme.md (Documentation)
- Purpose: Provides an overview, setup instructions, and usage examples.
- Content: Mirrors this detailed guide but in a concise format.
5. requirements.txt (Dependencies)
- Lists all required packages:
- openai (for API compatibility)
- requests (HTTP requests)
- duckduckgo-search (search integration)
- beautifulsoup4 (HTML parsing)
- fastapi (server framework)
- uvicorn (ASGI server)
- pydantic (data validation)
- python-dotenv (environment variables)
Data Flow Diagram (Conceptual):
Setup & Installation
-
Clone the Repository:
git clone https://github.com/gravixlayer/gravix-guides.git
cd gravix-guides/WebSearch-LLM -
Install Dependencies:
pip install -r requirements.txt -
Set Environment Variables:
- Obtain your API key from platform.gravixlayer.com.
export GRAVIXLAYER_API_KEY=your_api_key_here- Optionally, set
OPENAI_API_KEYas a fallback.
-
Start the Server:
uvicorn server:app --host 0.0.0.0 --port 8000- The server will run on
http://127.0.0.1:8000.
- The server will run on
Configuration
- API Key: Required for LLM inference via Gravix Layer. Set as
GRAVIXLAYER_API_KEY. - Model Selection: Specify in the request payload (e.g., "microsoft/phi-4" or "llama3.1:8b").
- Search Providers: Configurable in
websearch_tool.py. Uncomment Tavily integration if you have an API key. - Timeouts and Limits: HTTP requests have 10-second timeouts;
top_kmax is 10 for performance. - Environment: No internet access needed beyond search APIs; all processing is local.
Usage Example
-
Run the Server: As above.
-
Test with
test.py:python test.py- This sends a query about "Gravix Layer" and forces a web search.
- Expected Output: JSON with assistant response, sources, and search results.
-
Custom Client Integration:
- Use any OpenAI-compatible library (e.g., openai-python).
- Set base_url to your server:
client = OpenAI(base_url="http://127.0.0.1:8000/v1"). - Make chat.completions.create calls as usual.
Extending & Customizing
- Adding Tools: Append to
TOOLSinwebsearch_tool.pyand handle execution in the server loop. - Custom Search Providers: Modify
perform_web_searchto integrate APIs like Google, Bing, or custom scrapers. - LLM Prompt Tuning: Adjust system prompts in
server.pyfor better synthesis (e.g., emphasize citations). - Error Handling: Add logging or retries in
perform_web_search. - Production Enhancements: Add authentication, rate limiting, and async support in FastAPI.
- Model Compatibility: Test with other Gravix Layer models; adjust temperature for creativity vs. accuracy.
FAQ
Q: What if the search fails?
A: Fallbacks ensure results from alternative providers. If all fail, an error message is returned.
Q: Does it support streaming?
A: Not in this demo (returns 400 error), but FastAPI can be extended for it.
Q: How are sources cited?
A: The LLM is prompted to cite URLs. The server extracts them via regex for the response.
Q: Is this secure?
A: For demo purposes; in production, validate inputs to prevent injection attacks.
For questions or contributions, visit the GitHub repository.