

- Consistent, low-latency inference
- Guaranteed resource availability
- Scalable infrastructure for enterprise applications
Why Choose Dedicated Deployments?
When using shared inference, workloads compete for the same GPUs, leading to variability in speed and availability. Dedicated Deployments solve this by assigning hardware exclusively to your model.Replica Count (Horizontal Scaling)
Description: Configure how your deployment scales horizontally:- Start by setting the minimum replica count (
--min_replicas). This determines the baseline number of replicas your deployment will always maintain. - If you also specify a maximum replica count (
--max_replicas), autoscaling is automatically enabled. The system will scale the number of replicas between your minimum and maximum values based on demand. - If you do not specify a maximum replica count, only the minimum replica count is used, and the deployment will always run with that fixed number of replicas.
--max_replicas). Scaling is automatic if autoscaling is enabled; otherwise, replica count is fixed.
Autoscaling
Description: Autoscaling is automatically enabled when you specify a maximum replica count (--max_replicas). The system will scale the number of replicas between your minimum and maximum values based on demand, optimizing resource usage and cost.
How to Enable:
- Set both
--min_replicasand--max_replicaswhen creating your deployment.
- Autoscaling responds to traffic spikes and reduces idle resources.
- Configure thresholds for scaling events as needed.
Accelerator Count (Vertical Scaling)
Description: Assign multiple GPUs per replica to increase throughput for large models or batch processing. Example:- Supported values: 1, 2, 4, or 8.
- Higher counts are ideal for compute-intensive tasks.
Model Selection
Description: Choose your model from the supported list to deploy. The model determines the capabilities and use cases of your deployment. Example:- Refer to the documentation for available models.
- Select based on your application’s requirements.
Deployments via the UI
Initial Deployment Setup
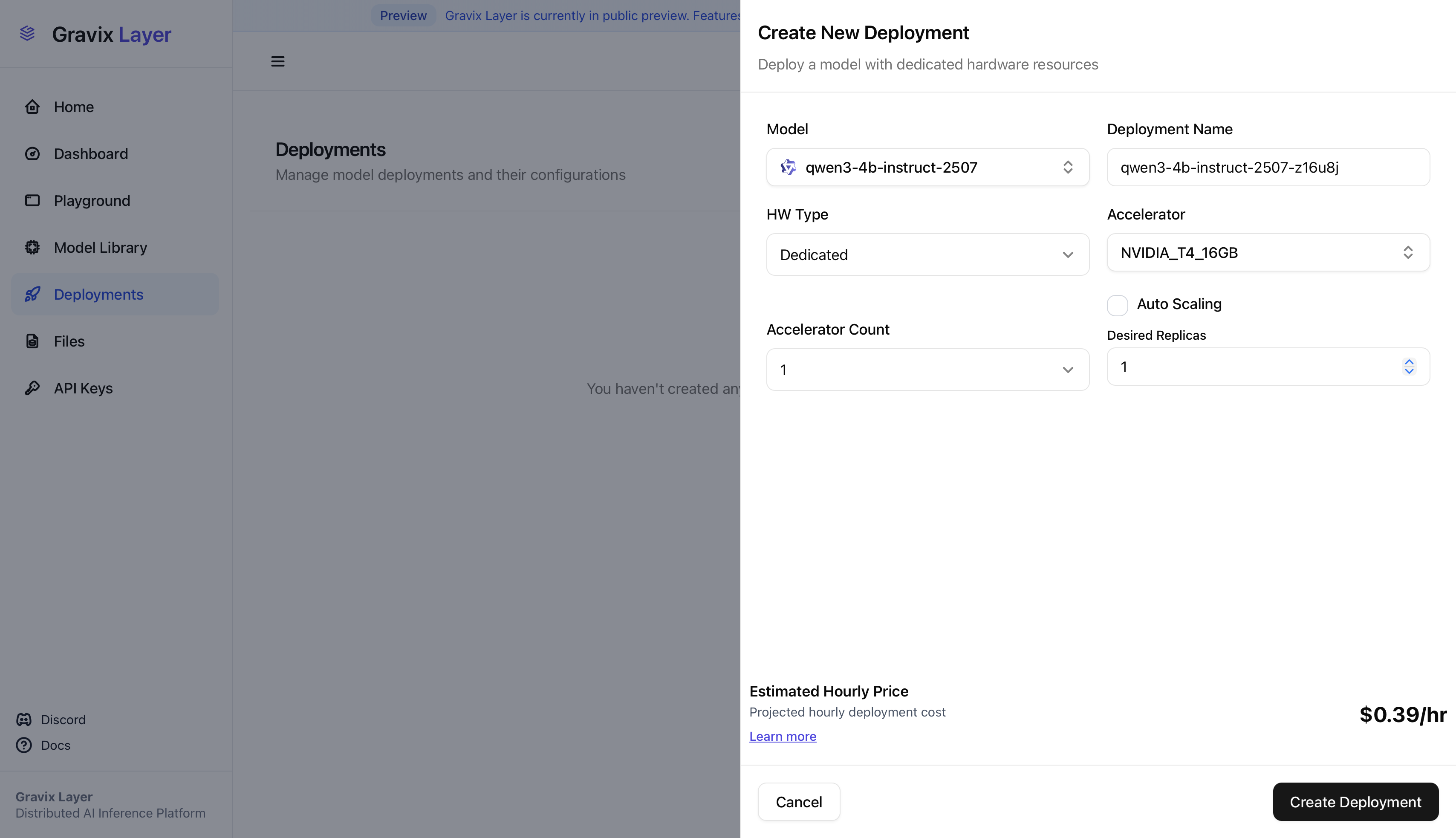
Creating Deployment
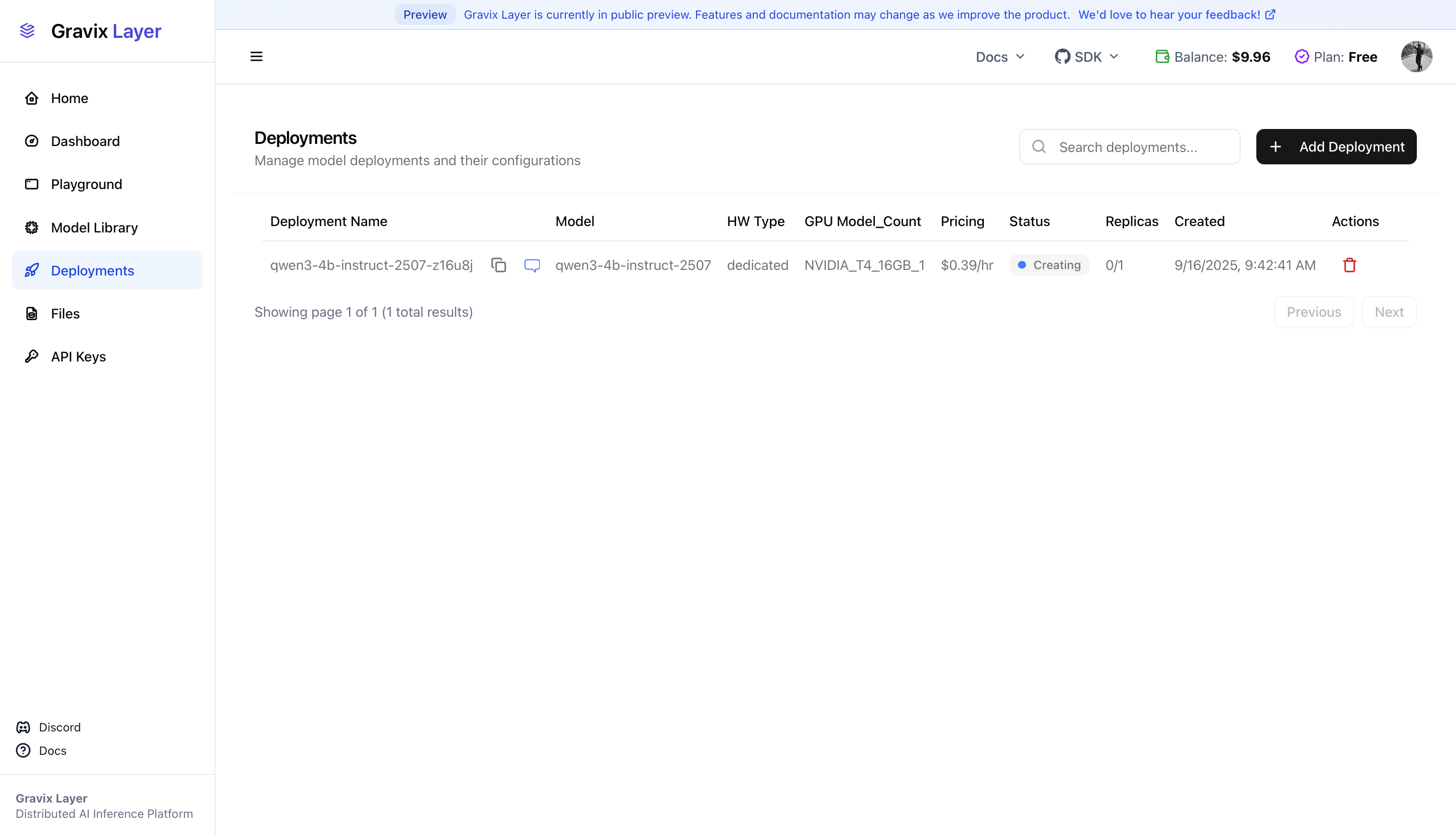
Created Deployment
Deployments using SDK
Explore Available Hardware
List available GPUs:Create a Deployment
Reserve hardware and deploy your model:Troubleshooting & Additional Resources
If you encounter issues with your deployment, consider the following:- Wait 5-10 minutes for initialization. Ensure deployment status is “running” before making requests.
- Slow responses: Review hardware capacity and consider adding replicas.
- Authentication errors: Ensure your API key is correctly set in environment variables.
- Unexpected costs: Remove unused deployments promptly.